Hand-crafted Feature Engineering
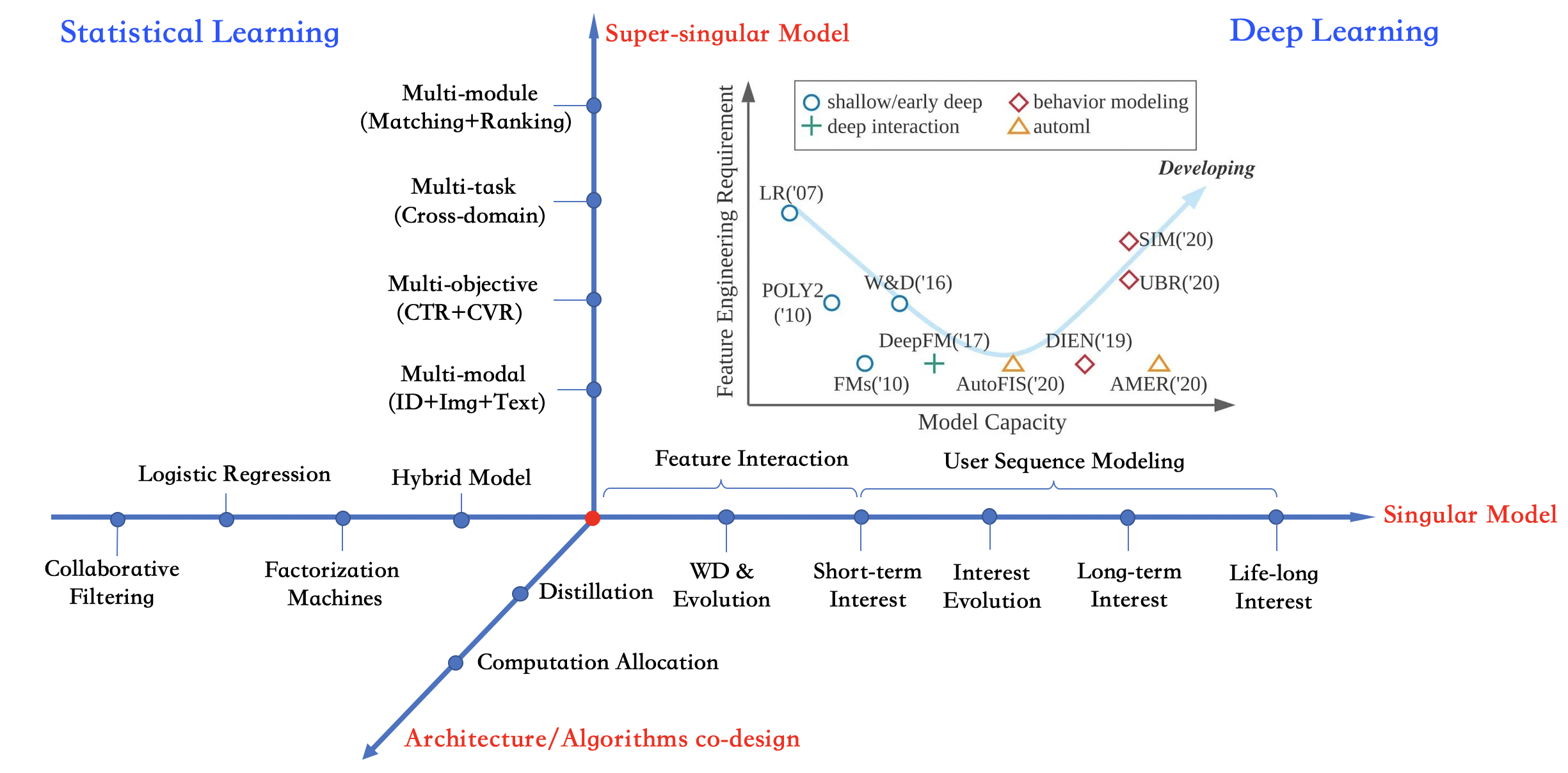
1. Feature Interaction Learning
no interaction, pair-wise interaction (inner-product, outer-product, convolutional, attention and etc.), high-order interaction (explicitly, implicit)
No interaction: LR, GBDT+LR
Pair-wise interaction:
inner-product: FM,
High-order interaction explicitly:
Youtube-DNN:
Wide&Deep
PNN
DeepFM
1.1 FM
FM explicitly model second-order cross features by parameterizing the weight of a cross feature as the inner product of the embedding vectors of the raw features.
1.2 Wide&Deep
wide part still needs feature engineering.
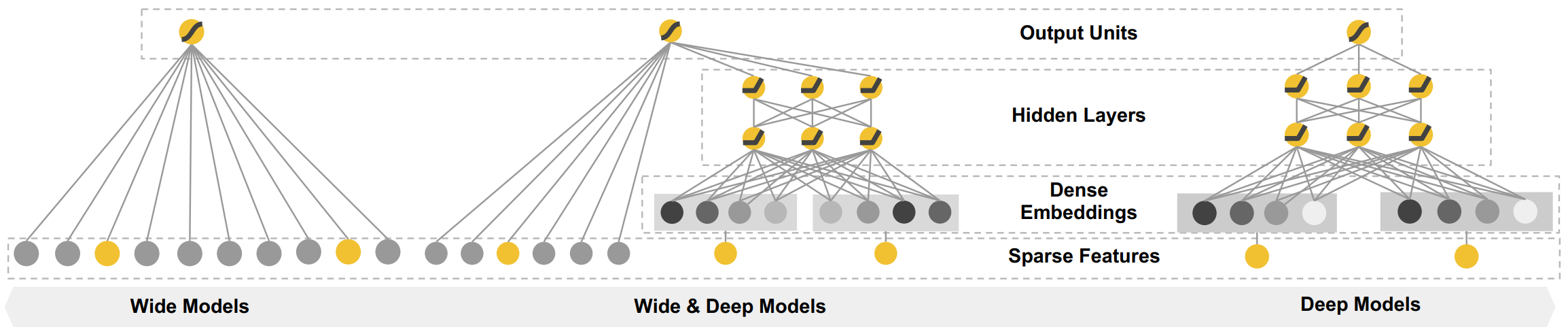
The bellow code is not the official code for wide&deep implementation, just show with comment the categorical features and dense features are combined.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 |
# reference: https://lyhue1991.github.io/eat_tensorflow2_in_30_days/chinese/5.%E4%B8%AD%E9%98%B6API/5-2%2C%E7%89%B9%E5%BE%81%E5%88%97feature_column/ import datetime import numpy as np import pandas as pd #from matplotlib import pyplot as plt import tensorflow as tf from tensorflow.keras import layers,models #打印日志 def printlog(info): nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') print("\n"+"=========="*8 + "%s"%nowtime) print(info+'...\n\n') #================================================================================ # 一,构建数据管道 #================================================================================ printlog("step1: prepare dataset...") dftrain_raw = pd.read_csv("dataset/titanic/train.csv") dftest_raw = pd.read_csv("dataset/titanic/test.csv") dfraw = pd.concat([dftrain_raw,dftest_raw]) def prepare_dfdata(dfraw): dfdata = dfraw.copy() dfdata.columns = [x.lower() for x in dfdata.columns] dfdata = dfdata.rename(columns={'survived':'label'}) dfdata = dfdata.drop(['passengerid','name'],axis = 1) for col,dtype in dict(dfdata.dtypes).items(): # 判断是否包含缺失值 if dfdata[col].hasnans: # 添加标识是否缺失列 dfdata[col + '_nan'] = pd.isna(dfdata[col]).astype('int32') # 填充 if dtype not in [np.object,np.str,np.unicode]: dfdata[col].fillna(dfdata[col].mean(),inplace = True) else: dfdata[col].fillna('',inplace = True) return(dfdata) dfdata = prepare_dfdata(dfraw) dftrain = dfdata.iloc[0:len(dftrain_raw),:] dftest = dfdata.iloc[len(dftrain_raw):,:] print(dftrain.head(5)) ''' label pclass sex age sibsp parch ticket fare cabin embarked label_nan age_nan fare_nan cabin_nan embarked_nan 0 0.0 3 male 22.0 1 0 A/5 21171 7.2500 S 0 0 0 1 0 1 1.0 1 female 38.0 1 0 PC 17599 71.2833 C85 C 0 0 0 0 0 2 1.0 3 female 26.0 0 0 STON/O2. 3101282 7.9250 S 0 0 0 1 0 3 1.0 1 female 35.0 1 0 113803 53.1000 C123 S 0 0 0 0 0 4 0.0 3 male 35.0 0 0 373450 8.0500 S 0 0 0 1 0 ''' # 从 dataframe 导入数据 def df_to_dataset(df, shuffle=True, batch_size=32): dfdata = df.copy() if 'label' not in dfdata.columns: ds = tf.data.Dataset.from_tensor_slices(dfdata.to_dict(orient = 'list')) else: labels = dfdata.pop('label') ds = tf.data.Dataset.from_tensor_slices((dfdata.to_dict(orient = 'list'), labels)) if shuffle: ds = ds.shuffle(buffer_size=len(dfdata)) ds = ds.batch(batch_size) ds_train = df_to_dataset(dftrain) ds_test = df_to_dataset(dftest) #================================================================================ # 二,定义特征列 #================================================================================ printlog("step2: make feature columns...") feature_columns = [] # 数值列 for col in ['age','fare','parch','sibsp'] + [ c for c in dfdata.columns if c.endswith('_nan')]: feature_columns.append(tf.feature_column.numeric_column(col)) ''' output: [22.0, 7.25, 0, 1] ''' # 分桶列 age = tf.feature_column.numeric_column('age') age_buckets = tf.feature_column.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65]) feature_columns.append(age_buckets) """ 'age': [22.0, 38.0, 26.0, 35.0, 35.0] output column with respect to boundaries numbers [[0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] [0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]] """ # 类别列 # 注意:所有的Catogorical Column类型最终都要通过indicator_column转换成Dense Column类型才能传入模型!! sex = tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_vocabulary_list( key='sex',vocabulary_list=["male", "female"])) feature_columns.append(sex) """ 'sex': ['male', 'female', 'female', 'female', 'male'], # First 5 samples output column nums [[1. 0.] [0. 1.] [0. 1.] [0. 1.] [1. 0.]] """ pclass = tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_vocabulary_list( key='pclass',vocabulary_list=[1,2,3])) feature_columns.append(pclass) """ 'pclass': [3, 1, 3, 1, 3], # First 5 samples output: [[0. 0. 1.] [1. 0. 0.] [0. 0. 1.] [1. 0. 0.] [0. 0. 1.]] """ ticket = tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_hash_bucket('ticket',3)) feature_columns.append(ticket) """ 'ticket': ['A/5 21171', 'PC 17599', 'STON/O2. 3101282', '113803', '373450'] output: [[1. 0. 0. 0.] [1. 0. 0. 0.] [0. 1. 0. 0.] [0. 0. 1. 0.] [0. 0. 0. 1.]] """ embarked = tf.feature_column.indicator_column( tf.feature_column.categorical_column_with_vocabulary_list( key='embarked',vocabulary_list=['S','C','B'])) feature_columns.append(embarked) # 嵌入列 cabin = tf.feature_column.embedding_column( tf.feature_column.categorical_column_with_hash_bucket('cabin',32),2) feature_columns.append(cabin) """ 'cabin': ['S', 'C', 'S', 'S', 'S'] output: [[-0.847916 -0.46826163] [ 0.12301657 -0.47506994] [-0.847916 -0.46826163] [-0.847916 -0.46826163] [-0.847916 -0.46826163]] """ # 交叉列 pclass_cate = tf.feature_column.categorical_column_with_vocabulary_list( key='pclass',vocabulary_list=[1,2,3]) """ 'pclass': [3, 1, 3, 1, 3], # First 5 samples output: [[0. 0. 1.] [1. 0. 0.] [0. 0. 1.] [1. 0. 0.] [0. 0. 1.]] """ crossed_feature = tf.feature_column.indicator_column( tf.feature_column.crossed_column([age_buckets, pclass_cate],hash_bucket_size=15)) """ plass: 3 age_buckets: 10 output: 15 [[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0.] [0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0.]] """ feature_columns.append(crossed_feature) #================================================================================ # 三,定义模型 #================================================================================ printlog("step3: define model...") tf.keras.backend.clear_session() model = tf.keras.Sequential([ layers.DenseFeatures(feature_columns), #将特征列放入到tf.keras.layers.DenseFeatures中!!! layers.Dense(64, activation='relu'), layers.Dense(64, activation='relu'), layers.Dense(1, activation='sigmoid') ]) #================================================================================ # 四,训练模型 #================================================================================ printlog("step4: train model...") model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy']) history = model.fit(ds_train, validation_data=ds_test, epochs=10) #================================================================================ # 五,评估模型 #================================================================================ printlog("step5: eval model...") model.summary() #%matplotlib inline #%config InlineBackend.figure_format = 'svg' #import matplotlib.pyplot as plt #def plot_metric(history, metric): # train_metrics = history.history[metric] # val_metrics = history.history['val_'+metric] # epochs = range(1, len(train_metrics) + 1) # plt.plot(epochs, train_metrics, 'bo--') # plt.plot(epochs, val_metrics, 'ro-') # plt.title('Training and validation '+ metric) # plt.xlabel("Epochs") # plt.ylabel(metric) # plt.legend(["train_"+metric, 'val_'+metric]) # plt.show() # ########DEBUG Reference Code########### #-*- encoding:utf-8 -*- import tensorflow as tf sess=tf.Session() """ # TEST feature_column.numeric_column #特征数据 features = { 'age': [22.0, 38.0, 26.0, 35.0, 35.0] } #特征列 age = tf.feature_column.numeric_column("age", default_value=0.0) #组合特征列 columns = [ age ] #输入层(数据,特征列) inputs = tf.feature_column.input_layer(features, columns) #初始化并运行 init = tf.global_variables_initializer() sess.run(tf.tables_initializer()) sess.run(init) v=sess.run(inputs) print(v) """ """ #特征数据 features = { 'age': [22.0, 38.0, 26.0, 35.0, 35.0] } #特征列 boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65] age = tf.feature_column.bucketized_column(tf.feature_column.numeric_column('age',default_value=0.0), boundaries=boundaries) #组合特征列 columns = [ age ] #输入层(数据,特征列) inputs = tf.feature_column.input_layer(features, columns) #初始化并运行 init = tf.global_variables_initializer() sess.run(tf.tables_initializer()) sess.run(init) v=sess.run(inputs) print(v) """ """ #特征数据 features = { 'sex': ['male', 'female', 'female', 'female', 'male'], # First 5 samples } #特征列 sex_column = tf.feature_column.categorical_column_with_vocabulary_list('sex', ['male', 'female']) sex_column = tf.feature_column.indicator_column(sex_column) #组合特征列 columns = [ sex_column ] #输入层(数据,特征列) inputs = tf.feature_column.input_layer(features, columns) #初始化并运行 init = tf.global_variables_initializer() sess.run(tf.tables_initializer()) sess.run(init) v=sess.run(inputs) print(v) """ """ #特征数据 features = { 'pclass': [3, 1, 3, 1, 3], # First 5 samples } #特征列 pclass_column = tf.feature_column.categorical_column_with_vocabulary_list('pclass', [1,2,3]) pclass_column = tf.feature_column.indicator_column(pclass_column) #组合特征列 columns = [ pclass_column ] #输入层(数据,特征列) inputs = tf.feature_column.input_layer(features, columns) #初始化并运行 init = tf.global_variables_initializer() sess.run(tf.tables_initializer()) sess.run(init) v=sess.run(inputs) print(v) """ """ #特征数据 features = { 'pclass': [3, 1, 3, 1, 3], # First 5 samples } #特征列 pclass_column = tf.feature_column.categorical_column_with_vocabulary_list('pclass', [1,2,3]) pclass_column = tf.feature_column.indicator_column(pclass_column) #组合特征列 columns = [ pclass_column ] #输入层(数据,特征列) inputs = tf.feature_column.input_layer(features, columns) #初始化并运行 init = tf.global_variables_initializer() sess.run(tf.tables_initializer()) sess.run(init) v=sess.run(inputs) print(v) """ """ #特征数据 features = { 'ticket': ['A/5 21171', 'PC 17599', 'STON/O2. 3101282', '113803', '373450'], } #特征列 ticket = tf.feature_column.categorical_column_with_hash_bucket('ticket', 4, dtype=tf.string) ticket = tf.feature_column.indicator_column(ticket) #组合特征列 columns = [ ticket ] #输入层(数据,特征列) inputs = tf.feature_column.input_layer(features, columns) #初始化并运行 init = tf.global_variables_initializer() sess.run(tf.tables_initializer()) sess.run(init) v=sess.run(inputs) print(v) """ """ #特征数据 features = { 'cabin': ['S', 'C', 'S', 'S', 'S'] } # 嵌入列 cabin = tf.feature_column.embedding_column( tf.feature_column.categorical_column_with_hash_bucket('cabin',32),2) #组合特征列 columns = [ cabin ] #输入层(数据,特征列) inputs = tf.feature_column.input_layer(features, columns) #初始化并运行 init = tf.global_variables_initializer() sess.run(tf.tables_initializer()) sess.run(init) v=sess.run(inputs) print(v) """ #特征数据 features = { 'age': [22.0, 38.0, 26.0, 35.0, 35.0], 'pclass': [3, 1, 3, 1, 3], } #特征列 age = tf.feature_column.numeric_column('age') age_buckets = tf.feature_column.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65]) pclass_cate = tf.feature_column.categorical_column_with_vocabulary_list( key='pclass',vocabulary_list=[1,2,3]) crossed_feature = tf.feature_column.indicator_column( tf.feature_column.crossed_column([age_buckets, pclass_cate],hash_bucket_size=15)) #组合特征列 columns = [ crossed_feature ] #输入层(数据,特征列) inputs = tf.feature_column.input_layer(features, columns) #初始化并运行 init = tf.global_variables_initializer() sess.run(tf.tables_initializer()) sess.run(init) v=sess.run(inputs) print(v) |
1.3 DeepFM
DeepFM replace the wide part in WD and shares the feature embedding between the FM and deep component.
1.4 Deep & Cross Network (DCN)
Explicitly capture the feature interaction.
Learn predictive cross features of bounded degrees, and requires no manual feature engineering or exhaustive searching.
(1) Embedding and Stacking Layer: stack the embedding vectors, along with the normalized dense features to form the input.
![\[ \mathbf{x}_{0}=\left[\mathbf{x}_{\mathrm{embed}, 1}^{T}, \ldots, \mathbf{x}_{\text {embed }, k}^{T}, \mathbf{x}_{\text {dense }}^{T}\right] \]](http://www.liaoyong.net/wp-content/ql-cache/quicklatex.com-e52344d227525fe5cd830d6d87de7860_l3.png "Rendered by QuickLaTeX.com")
(2) Cross Network: apply explicit feature crossing in an efficient way.
![\[ \mathbf{x}_{l+1}=\mathbf{x}_{0} \mathbf{x}_{l}^{T} \mathbf{w}_{l}+\mathbf{b}_{l}+\mathbf{x}_{l}=f\left(\mathbf{x}_{l}, \mathbf{w}_{l}, \mathbf{b}_{l}\right)+\mathbf{x}_{l} \]](http://www.liaoyong.net/wp-content/ql-cache/quicklatex.com-8fe88aaec2054d4fac5a65e843ca5436_l3.png "Rendered by QuickLaTeX.com")
(3) Deep Network:
![\[ \mathbf{h}_{l+1}=f\left(W_{l} \mathbf{h}_{l}+\mathbf{b}_{l}\right) \]](http://www.liaoyong.net/wp-content/ql-cache/quicklatex.com-ac5ec4bde3563c51d67f4e6b1b6d2b14_l3.png "Rendered by QuickLaTeX.com")
(4) Combination Layer:
![\[ p=\sigma\left(\left[\mathbf{x}_{L_{1}}^{T}, \mathbf{h}_{L_{2}}^{T}\right] \mathbf{w}_{\text {logits }}\right) \]](http://www.liaoyong.net/wp-content/ql-cache/quicklatex.com-9ae6014ae4f92862ca79399ad833ab0d_l3.png "Rendered by QuickLaTeX.com")
loss fucntion:
![\[ \operatorname{loss}=-\frac{1}{N} \sum_{i=1}^{N} y_{i} \log \left(p_{i}\right)+\left(1-y_{i}\right) \log \left(1-p_{i}\right)+\lambda \sum_{l}\left\|\mathbf{w}_{l}\right\|^{2} \]](http://www.liaoyong.net/wp-content/ql-cache/quicklatex.com-32dba03aad2709a008deddc37054971a_l3.png "Rendered by QuickLaTeX.com")
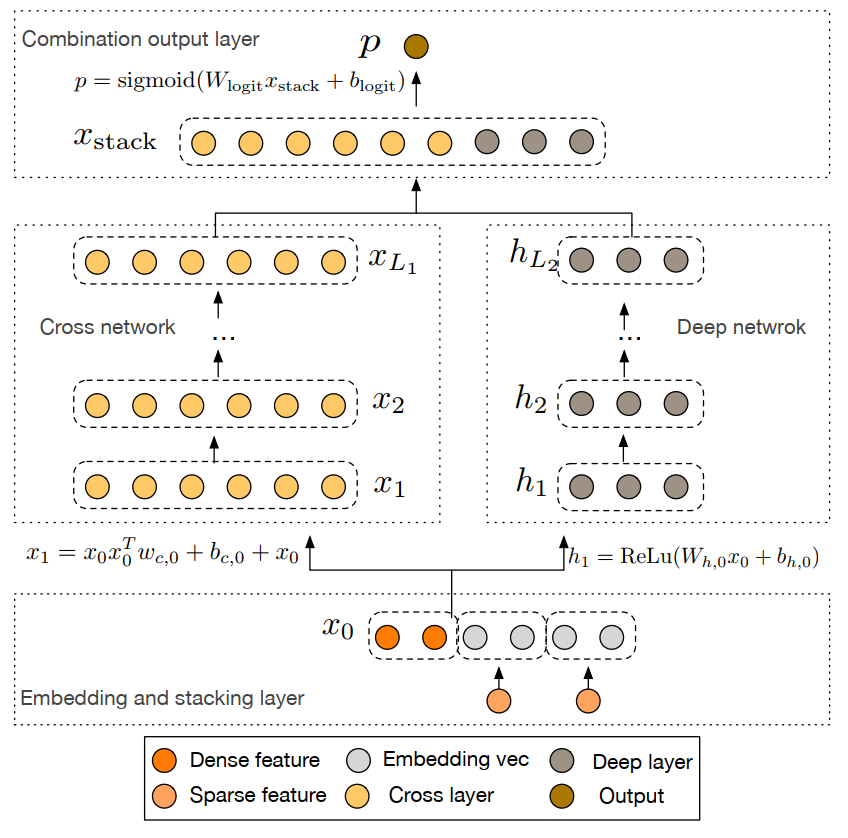
DCN-V2
DCN-V2
1.5 eXtreme Deep Factorization Machine (xDeepFM)
Models the low-order and high-order feature interactions in an explicit way
Above FMs model feature interaction with the same weight, ignoring the relative importance, Attentional Factorization Machines(AFM) uses the attention network to learn the weights of feature interactions.
1.6 Attentional Factorization Machines (AFM)
Reference.
1.7 NFM
Reference.
1.8 Feature Importance and Bilinear feature Interaction NETwork (FiBiNet)
SENET is used to boost feature discriminability.

SENET layer: Squeeze, excitation and re-weight steps.
Bilinear-interaction Layer: Combines the inner product and Hadamard product to learn the feature interactions.
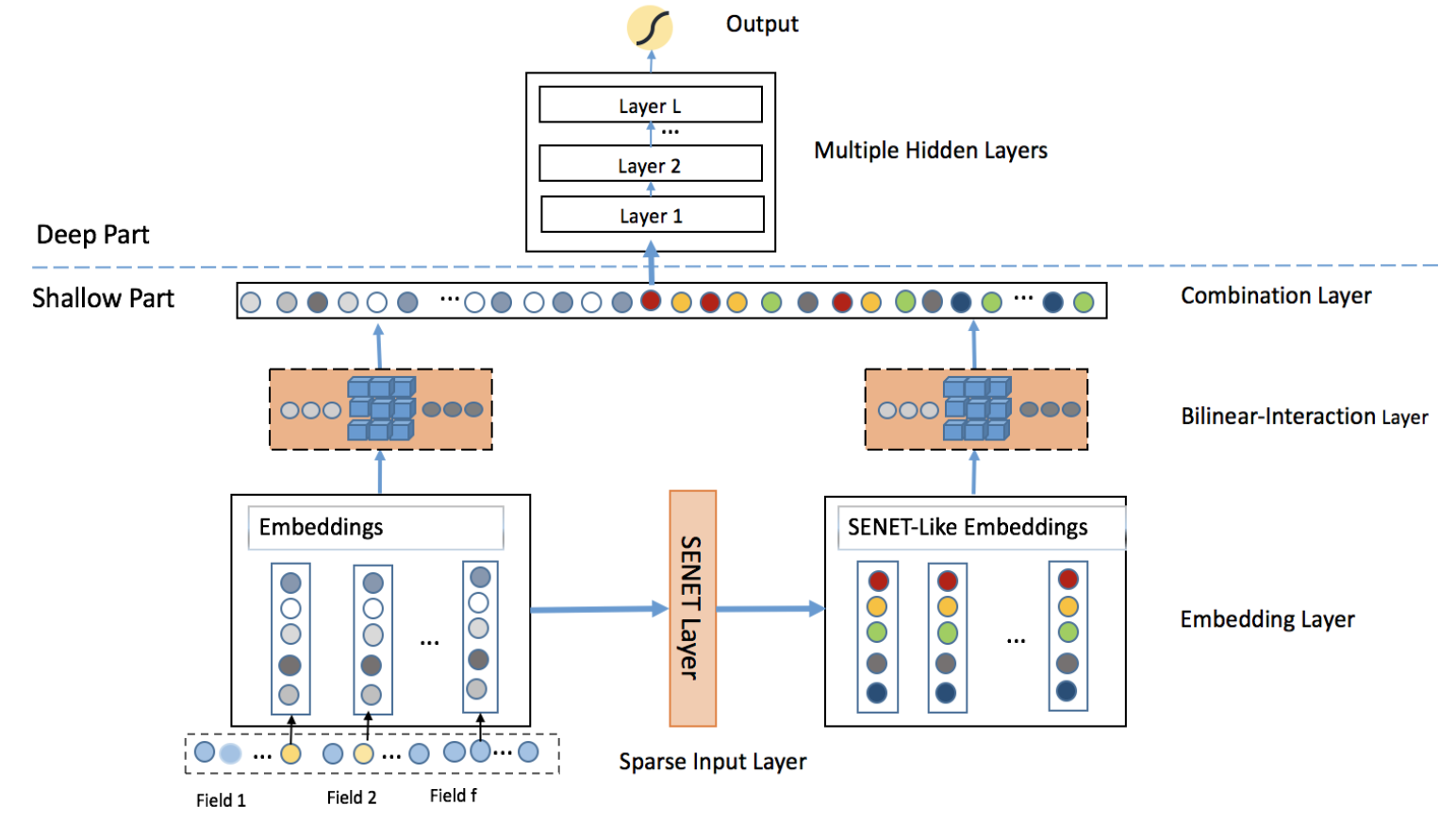
Both the origin embeddings and re-weighted embedding should be sent to the bilinear-interaction layer.
Code snippet.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 |
# -*- coding: utf-8 -*- """ Created on Fri Nov 19 15:46:01 2021 @author: luoh1 """ import numpy as np import tensorflow as tf from tensorflow.keras import layers from tensorflow.keras import Model from tensorflow.keras.layers import Layer class SELayer(Layer): """ Squenzee and Excitation Layer in FiBiNET """ def __init__(self, field_size, reduction_ratio, pooling = 'mean'): super(SELayer, self).__init__() self.field_size = field_size self.reduction_ratio = reduction_ratio self.pooling = pooling self.reduction_size = max(1, field_size // reduction_ratio) self.excitation = tf.keras.Sequential() self.excitation.add(layers.Dense(self.reduction_size, input_shape =(field_size,), use_bias = False)) self.excitation.add(layers.Activation('relu')) self.excitation.add(layers.Dense(field_size, input_shape = (self.reduction_size,), use_bias = False)) self.excitation.add(layers.Activation('relu')) def call(self, x): """ x : batch * field_size * embed_dim """ # squeeze if self.pooling == 'mean': z = tf.reduce_mean(x, axis = -1) elif self.pooling == 'max': z = tf.reduce_max(x, axis = -1) else: raise NotImplementedError # excitation A = self.excitation(z) # reweight embedding V = tf.multiply(x, tf.expand_dims(A, axis=2)) return V class BilinearInteraction(Layer): """ BilinearInteraction Layer in FiBiNET """ def __init__(self, field_size, embed_dim, bilinear_type = 'interaction'): super(BilinearInteraction, self).__init__() self.field_size = field_size self.embed_dim = embed_dim self.bilinear_type = bilinear_type def build(self, input_shape): if self.bilinear_type == 'all': self.W = self.add_weight(name = 'bilinear_W', shape = (self.embed_dim, self.embed_dim), initializer = 'random_normal', trainable = True) elif self.bilinear_type == 'each': self.W_List = [self.add_weight(name = 'bilinear_W_{}'.format(i), shape = (self.embed_dim, self.embed_dim), initializer = 'random_normal', trainable = True) for i in range(self.field_size)] elif self.bilinear_type == 'interaction': self.W_List = [self.add_weight(name = 'bilinear_W_{}'.format(i), shape = (self.embed_dim, self.embed_dim), initializer = 'random_normal', trainable = True) for i in range(self.field_size) for j in range(i+1, self.field_size)] else: raise NotImplementedError def call(self, x): """ x : batch * field_size * embed_dim """ x = tf.split(x, self.field_size, axis=1) # 将每个field拿出来 p = [] if self.bilinear_type == 'all': for i in range(self.field_size): v_i = x[i] for j in range(i+1, self.field_size): v_j = x[j] tmp = tf.tensordot(v_i, self.W, axes=(-1,0)) tmp = tf.multiply(tmp, v_j) p.append(tmp) elif self.bilinear_type == 'each': for i in range(self.field_size): v_i = x[i] for j in range(i+1, self.field_size): v_j = x[j] tmp = tf.tensordot(v_i, self.W_List[i], axes=(-1,0)) tmp = tf.multiply(tmp, v_j) p.append(tmp) elif self.bilinear_type == 'interaction': num = 0 # 取 Vi, Vj 对应的W for i in range(self.field_size): v_i = x[i] for j in range(i+1, self.field_size): v_j = x[j] tmp = tf.tensordot(v_i, self.W_List[num], axes=(-1,0)) tmp = tf.multiply(tmp, v_j) p.append(tmp) num += 1 else: raise NotImplementedError p = tf.concat(p, axis = 1) return p class FiBiNET(Model): """ Feature Importance and Bilinear feature Interaction Net """ def __init__(self, feature_fields, embed_dim, reduction_ratio, pooling = 'mean', mlp_dims = (64, 32), dropout=0.): super(FiBiNET, self).__init__() self.field_size = len(feature_fields) self.offsets = np.array((0, *np.cumsum(feature_fields)[:-1]), dtype = np.long) # Embedding Layer self.embedding = layers.Embedding(sum(feature_fields) + 1, embed_dim, input_length = self.field_size) # SE Layer self.SELayer = SELayer(self.field_size, reduction_ratio) # Bilinear Layer self.Bilinear = BilinearInteraction(self.field_size, embed_dim) # Final DNN self.embed_out_dim = self.field_size * (self.field_size - 1) * embed_dim input_dim = self.embed_out_dim self.mlp = tf.keras.Sequential() for mlp_dim in mlp_dims: self.mlp.add(layers.Dense(mlp_dim, input_shape = [input_dim,])) self.mlp.add(layers.BatchNormalization()) self.mlp.add(layers.Activation('relu')) self.mlp.add(layers.Dropout(dropout)) input_dim = mlp_dim self.mlp.add(layers.Dense(1, input_shape = [input_dim,])) def call(self, x): """ x : batch * field_size """ x = x + self.offsets # embedding_x embed_x = self.embedding(x) # SENet-like embedding SE_embed_x = self.SELayer(embed_x) batch = tf.shape(embed_x)[0] # Bilinear interaction p = tf.reshape(self.Bilinear(embed_x), (batch, -1)) se_p = tf.reshape(self.Bilinear(SE_embed_x), (batch, -1)) # final DNN concat_p = tf.concat([p, se_p], axis=1) res = tf.sigmoid(self.mlp(concat_p)) return res |
1.9 CAN
Reference
1.10 AutoInt+
Reference
1.11 ONN
Reference
2. Behavior Sequence Modeling
3. Multi-task Learning
4. Multi-modal Learning
Cross-domain Learning